![]()
Databricks-Machine-Learning-Associate Updated Exam Dumps [2025] Practice Valid Exam Dumps Question
Databricks-Machine-Learning-Associate Sample with Accurate & Updated Questions
Databricks Databricks-Machine-Learning-Associate Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
NEW QUESTION # 40
An organization is developing a feature repository and is electing to one-hot encode all categorical feature variables. A data scientist suggests that the categorical feature variables should not be one-hot encoded within the feature repository.
Which of the following explanations justifies this suggestion?
- A. One-hot encoding is not a common strategy for representing categorical feature variables numerically.
- B. One-hot encoding is dependent on the target variable's values which differ for each apaplication.
- C. One-hot encoding is computationally intensive and should only be performed on small samples of training sets for individual machine learning problems.
- D. One-hot encoding is a potentially problematic categorical variable strategy for some machine learning algorithms.
Answer: D
Explanation:
The suggestion not to one-hot encode categorical feature variables within the feature repository is justified because one-hot encoding can be problematic for some machine learning algorithms. Specifically, one-hot encoding increases the dimensionality of the data, which can be computationally expensive and may lead to issues such as multicollinearity and overfitting. Additionally, some algorithms, such as tree-based methods, can handle categorical variables directly without requiring one-hot encoding.
Reference:
Databricks documentation on feature engineering: Feature Engineering
NEW QUESTION # 41
A data scientist is performing hyperparameter tuning using an iterative optimization algorithm. Each evaluation of unique hyperparameter values is being trained on a single compute node. They are performing eight total evaluations across eight total compute nodes. While the accuracy of the model does vary over the eight evaluations, they notice there is no trend of improvement in the accuracy. The data scientist believes this is due to the parallelization of the tuning process.
Which change could the data scientist make to improve their model accuracy over the course of their tuning process?
- A. Change the iterative optimization algorithm used to facilitate the tuning process.
- B. Change the number of compute nodes and the number of evaluations to be much larger but equal.
- C. Change the number of compute nodes to be half or less than half of the number of evaluations.
- D. Change the number of compute nodes to be double or more than double the number of evaluations.
Answer: A
Explanation:
The lack of improvement in model accuracy across evaluations suggests that the optimization algorithm might not be effectively exploring the hyperparameter space. Iterative optimization algorithms like Tree-structured Parzen Estimators (TPE) or Bayesian Optimization can adapt based on previous evaluations, guiding the search towards more promising regions of the hyperparameter space.
Changing the optimization algorithm can lead to better utilization of the information gathered during each evaluation, potentially improving the overall accuracy.
Reference:
Hyperparameter Optimization with Hyperopt
NEW QUESTION # 42
A machine learning engineer has grown tired of needing to install the MLflow Python library on each of their clusters. They ask a senior machine learning engineer how their notebooks can load the MLflow library without installing it each time. The senior machine learning engineer suggests that they use Databricks Runtime for Machine Learning.
Which of the following approaches describes how the machine learning engineer can begin using Databricks Runtime for Machine Learning?
- A. They can set the runtime-version variable in their Spark session to "ml".
- B. They can add a line enabling Databricks Runtime ML in their init script when creating their clusters.
- C. They can check the Databricks Runtime ML box when creating their clusters.
- D. They can select a Databricks Runtime ML version from the Databricks Runtime Version dropdown when creating their clusters.
Answer: D
Explanation:
The Databricks Runtime for Machine Learning includes pre-installed packages and libraries essential for machine learning and deep learning, including MLflow. To use it, the machine learning engineer can simply select an appropriate Databricks Runtime ML version from the "Databricks Runtime Version" dropdown menu while creating their cluster. This selection ensures that all necessary machine learning libraries, including MLflow, are pre-installed and ready for use, avoiding the need to manually install them each time.
Reference
Databricks documentation on creating clusters: https://docs.databricks.com/clusters/create.html
NEW QUESTION # 43
A machine learning engineer has identified the best run from an MLflow Experiment. They have stored the run ID in the run_id variable and identified the logged model name as "model". They now want to register that model in the MLflow Model Registry with the name "best_model".
Which lines of code can they use to register the model associated with run_id to the MLflow Model Registry?
- A. mlflow.register_model(run_id, "best_model")
- B. millow.register_model(f"runs:/{run_id)/model")
- C. mlflow.register_model(f"runs:/{run_id}/best_model", "model")
- D. mlflow.register_model(f"runs:/{run_id}/model", "best_model")
Answer: D
Explanation:
To register a model that has been identified by a specific run_id in the MLflow Model Registry, the appropriate line of code is:
mlflow.register_model(f"runs:/{run_id}/model", "best_model")
This code correctly specifies the path to the model within the run (runs:/{run_id}/model) and registers it under the name "best_model" in the Model Registry. This allows the model to be tracked, managed, and transitioned through different stages (e.g., Staging, Production) within the MLflow ecosystem.
Reference
MLflow documentation on model registry: https://www.mlflow.org/docs/latest/model-registry.html#registering-a-model
NEW QUESTION # 44
A data scientist wants to efficiently tune the hyperparameters of a scikit-learn model. They elect to use the Hyperopt library's fmin operation to facilitate this process. Unfortunately, the final model is not very accurate. The data scientist suspects that there is an issue with the objective_function being passed as an argument to fmin.
They use the following code block to create the objective_function:
Which of the following changes does the data scientist need to make to their objective_function in order to produce a more accurate model?
- A. Add test set validation process
- B. Replace the fmin operation with the fmax operation
- C. Add a random_state argument to the RandomForestRegressor operation
- D. Replace the r2 return value with -r2
- E. Remove the mean operation that is wrapping the cross_val_score operation
Answer: D
Explanation:
When using the Hyperopt library with fmin, the goal is to find the minimum of the objective function. Since you are using cross_val_score to calculate the R2 score which is a measure of the proportion of the variance for a dependent variable that's explained by an independent variable(s) in a regression model, higher values are better. However, fmin seeks to minimize the objective function, so to align with fmin's goal, you should return the negative of the R2 score (-r2). This way, by minimizing the negative R2, fmin is effectively maximizing the R2 score, which can lead to a more accurate model.
Reference
Hyperopt Documentation: http://hyperopt.github.io/hyperopt/
Scikit-Learn documentation on model evaluation: https://scikit-learn.org/stable/modules/model_evaluation.html
NEW QUESTION # 45
A data scientist is using MLflow to track their machine learning experiment. As a part of each of their MLflow runs, they are performing hyperparameter tuning. The data scientist would like to have one parent run for the tuning process with a child run for each unique combination of hyperparameter values. All parent and child runs are being manually started with mlflow.start_run.
Which of the following approaches can the data scientist use to accomplish this MLflow run organization?
- A. They can start each child run inside the parent run's indented code block using mlflow.start runO
- B. They can start each child run with the same experiment ID as the parent run
- C. They can specify nested=True when starting the parent run for the tuning process
- D. They can turn on Databricks Autologging
- E. They can specify nested=True when starting the child run for each unique combination of hyperparameter values
Answer: E
Explanation:
To organize MLflow runs with one parent run for the tuning process and a child run for each unique combination of hyperparameter values, the data scientist can specify nested=True when starting the child run. This approach ensures that each child run is properly nested under the parent run, maintaining a clear hierarchical structure for the experiment. This nesting helps in tracking and comparing different hyperparameter combinations within the same tuning process.
Reference:
MLflow Documentation (Managing Nested Runs).
NEW QUESTION # 46
A machine learning engineer has been notified that a new Staging version of a model registered to the MLflow Model Registry has passed all tests. As a result, the machine learning engineer wants to put this model into production by transitioning it to the Production stage in the Model Registry.
From which of the following pages in Databricks Machine Learning can the machine learning engineer accomplish this task?
- A. The model page in the MLflow Model Registry
- B. The model version page in the MLflow Model Registry
- C. The experiment page in the Experiments observatory
- D. The home page of the MLflow Model Registry
Answer: B
Explanation:
The machine learning engineer can transition a model version to the Production stage in the Model Registry from the model version page. This page provides detailed information about a specific version of a model, including its metrics, parameters, and current stage. From here, the engineer can perform stage transitions, moving the model from Staging to Production after it has passed all necessary tests.
Reference
Databricks documentation on MLflow Model Registry: https://docs.databricks.com/applications/mlflow/model-registry.html#model-version
NEW QUESTION # 47
A data scientist has developed a random forest regressor rfr and included it as the final stage in a Spark MLPipeline pipeline. They then set up a cross-validation process with pipeline as the estimator in the following code block:
Which of the following is a negative consequence of including pipeline as the estimator in the cross-validation process rather than rfr as the estimator?
- A. The process will be unable to parallelize tuning due to the distributed nature of pipeline
- B. The process will have a longer runtime because all stages of pipeline need to be refit or retransformed with each mode
- C. The process will leak data prep information from the validation sets to the training sets for each model
- D. The process will leak data from the training set to the test set during the evaluation phase
Answer: B
Explanation:
Including the entire pipeline as the estimator in the cross-validation process means that all stages of the pipeline, including data preprocessing steps like string indexing and vector assembling, will be refit or retransformed for each fold of the cross-validation. This results in a longer runtime because each fold requires re-execution of these preprocessing steps, which can be computationally expensive.
If only the random forest regressor (rfr) were included as the estimator, the preprocessing steps would be performed once, and only the model fitting would be repeated for each fold, significantly reducing the computational overhead.
Reference:
Databricks documentation on cross-validation: Cross Validation
NEW QUESTION # 48
An organization is developing a feature repository and is electing to one-hot encode all categorical feature variables. A data scientist suggests that the categorical feature variables should not be one-hot encoded within the feature repository.
Which of the following explanations justifies this suggestion?
- A. One-hot encoding is not a common strategy for representing categorical feature variables numerically.
- B. One-hot encoding is not supported by most machine learning libraries.
- C. One-hot encoding is dependent on the target variable's values which differ for each application.
- D. One-hot encoding is computationally intensive and should only be performed on small samples of training sets for individual machine learning problems.
- E. One-hot encoding is a potentially problematic categorical variable strategy for some machine learning algorithms.
Answer: E
Explanation:
One-hot encoding transforms categorical variables into a format that can be provided to machine learning algorithms to better predict the output. However, when done prematurely or universally within a feature repository, it can be problematic:
Dimensionality Increase: One-hot encoding significantly increases the feature space, especially with high cardinality features, which can lead to high memory consumption and slower computation.
Model Specificity: Some models handle categorical variables natively (like decision trees and boosting algorithms), and premature one-hot encoding can lead to inefficiency and loss of information (e.g., ordinal relationships).
Sparse Matrix Issue: It often results in a sparse matrix where most values are zero, which can be inefficient in both storage and computation for some algorithms.
Generalization vs. Specificity: Encoding should ideally be tailored to specific models and use cases rather than applied generally in a feature repository.
Reference
"Feature Engineering and Selection: A Practical Approach for Predictive Models" by Max Kuhn and Kjell Johnson (CRC Press, 2019).
NEW QUESTION # 49
A machine learning engineer is trying to perform batch model inference. They want to get predictions using the linear regression model saved at the path model_uri for the DataFrame batch_df.
batch_df has the following schema:
customer_id STRING
The machine learning engineer runs the following code block to perform inference on batch_df using the linear regression model at model_uri:
In which situation will the machine learning engineer's code block perform the desired inference?
- A. When the Feature Store feature set was logged with the model at model_uri
- B. When all of the features used by the model at model_uri are in a Spark DataFrame in the PySpark
- C. This code block will not perform the desired inference in any situation.
- D. When all of the features used by the model at model_uri are in a single Feature Store table
- E. When the model at model_uri only uses customer_id as a feature
Answer: A
Explanation:
The code block provided by the machine learning engineer will perform the desired inference when the Feature Store feature set was logged with the model at model_uri. This ensures that all necessary feature transformations and metadata are available for the model to make predictions. The Feature Store in Databricks allows for seamless integration of features and models, ensuring that the required features are correctly used during inference.
Reference:
Databricks documentation on Feature Store: Feature Store in Databricks
NEW QUESTION # 50
In which of the following situations is it preferable to impute missing feature values with their median value over the mean value?
- A. When the features contain no missing no values
- B. When the features contain a lot of extreme outliers
- C. When the features are of the categorical type
- D. When the features contain no outliers
- E. When the features are of the boolean type
Answer: B
Explanation:
Imputing missing values with the median is often preferred over the mean in scenarios where the data contains a lot of extreme outliers. The median is a more robust measure of central tendency in such cases, as it is not as heavily influenced by outliers as the mean. Using the median ensures that the imputed values are more representative of the typical data point, thus preserving the integrity of the dataset's distribution. The other options are not specifically relevant to the question of handling outliers in numerical data.
Reference:
Data Imputation Techniques (Dealing with Outliers).
NEW QUESTION # 51
The implementation of linear regression in Spark ML first attempts to solve the linear regression problem using matrix decomposition, but this method does not scale well to large datasets with a large number of variables.
Which of the following approaches does Spark ML use to distribute the training of a linear regression model for large data?
- A. Spark ML cannot distribute linear regression training
- B. Logistic regression
- C. Iterative optimization
- D. Least-squares method
- E. Singular value decomposition
Answer: C
Explanation:
For large datasets with many variables, Spark ML distributes the training of a linear regression model using iterative optimization methods. Specifically, Spark ML employs algorithms such as Gradient Descent or L-BFGS (Limited-memory Broyden-Fletcher-Goldfarb-Shanno) to iteratively minimize the loss function. These iterative methods are suitable for distributed computing environments and can handle large-scale data efficiently by partitioning the data across nodes in a cluster and performing parallel updates.
Reference:
Spark MLlib Documentation (Linear Regression with Iterative Optimization).
NEW QUESTION # 52
Which of the following describes the relationship between native Spark DataFrames and pandas API on Spark DataFrames?
- A. pandas API on Spark DataFrames are more performant than Spark DataFrames
- B. pandas API on Spark DataFrames are less mutable versions of Spark DataFrames
- C. pandas API on Spark DataFrames are made up of Spark DataFrames and additional metadata
- D. pandas API on Spark DataFrames are single-node versions of Spark DataFrames with additional metadata
Answer: C
Explanation:
The pandas API on Spark DataFrames are made up of Spark DataFrames with additional metadata. The pandas API on Spark aims to provide the pandas-like experience with the scalability and distributed nature of Spark. It allows users to work with pandas functions on large datasets by leveraging Spark's underlying capabilities.
Reference:
Databricks documentation on pandas API on Spark: pandas API on Spark
NEW QUESTION # 53
A team is developing guidelines on when to use various evaluation metrics for classification problems. The team needs to provide input on when to use the F1 score over accuracy.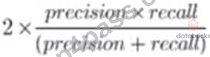
Which of the following suggestions should the team include in their guidelines?
- A. The F1 score should be utilized over accuracy when the number of actual positive cases is identical to the number of actual negative cases.
- B. The F1 score should be utilized over accuracy when there are greater than two classes in the target variable.
- C. The F1 score should be utilized over accuracy when identifying true positives and true negatives are equally important to the business problem.
- D. The F1 score should be utilized over accuracy when there is significant imbalance between positive and negative classes and avoiding false negatives is a priority.
Answer: D
Explanation:
The F1 score is the harmonic mean of precision and recall and is particularly useful in situations where there is a significant imbalance between positive and negative classes. When there is a class imbalance, accuracy can be misleading because a model can achieve high accuracy by simply predicting the majority class. The F1 score, however, provides a better measure of the test's accuracy in terms of both false positives and false negatives.
Specifically, the F1 score should be used over accuracy when:
There is a significant imbalance between positive and negative classes.
Avoiding false negatives is a priority, meaning recall (the ability to detect all positive instances) is crucial.
In this scenario, the F1 score balances both precision (the ability to avoid false positives) and recall, providing a more meaningful measure of a model's performance under these conditions.
Reference:
Databricks documentation on classification metrics: Classification Metrics
NEW QUESTION # 54
A data scientist wants to tune a set of hyperparameters for a machine learning model. They have wrapped a Spark ML model in the objective function objective_function and they have defined the search space search_space.
As a result, they have the following code block:
Which of the following changes do they need to make to the above code block in order to accomplish the task?
- A. Remove the algo=tpe.suggest argument
- B. Change SparkTrials() to Trials()
- C. Reduce num_evals to be less than 10
- D. Change fmin() to fmax()
- E. Remove the trials=trials argument
Answer: B
Explanation:
The SparkTrials() is used to distribute trials of hyperparameter tuning across a Spark cluster. If the environment does not support Spark or if the user prefers not to use distributed computing for this purpose, switching to Trials() would be appropriate. Trials() is the standard class for managing search trials in Hyperopt but does not distribute the computation. If the user is encountering issues with SparkTrials() possibly due to an unsupported configuration or an error in the cluster setup, using Trials() can be a suitable change for running the optimization locally or in a non-distributed manner.
Reference
Hyperopt documentation: http://hyperopt.github.io/hyperopt/
NEW QUESTION # 55
A data scientist has a Spark DataFrame spark_df. They want to create a new Spark DataFrame that contains only the rows from spark_df where the value in column discount is less than or equal 0.
Which of the following code blocks will accomplish this task?
- A. spark_df[spark_df["discount"] <= 0]
- B. spark_df.loc[:,spark_df["discount"] <= 0]
- C. spark_df.loc(spark_df["discount"] <= 0, :]
- D. spark_df.filter (col("discount") <= 0)
Answer: D
Explanation:
To filter rows in a Spark DataFrame based on a condition, the filter method is used. In this case, the condition is that the value in the "discount" column should be less than or equal to 0. The correct syntax uses the filter method along with the col function from pyspark.sql.functions.
Correct code:
from pyspark.sql.functions import col filtered_df = spark_df.filter(col("discount") <= 0) Option A and D use Pandas syntax, which is not applicable in PySpark. Option B is closer but misses the use of the col function.
Reference:
PySpark SQL Documentation
NEW QUESTION # 56
A data scientist has replaced missing values in their feature set with each respective feature variable's median value. A colleague suggests that the data scientist is throwing away valuable information by doing this.
Which of the following approaches can they take to include as much information as possible in the feature set?
- A. Remove all feature variables that originally contained missing values from the feature set
- B. Create a binary feature variable for each feature that contained missing values indicating whether each row's value has been imputed
- C. Refrain from imputing the missing values in favor of letting the machine learning algorithm determine how to handle them
- D. Create a constant feature variable for each feature that contained missing values indicating the percentage of rows from the feature that was originally missing
- E. Impute the missing values using each respective feature variable's mean value instead of the median value
Answer: B
Explanation:
By creating a binary feature variable for each feature with missing values to indicate whether a value has been imputed, the data scientist can preserve information about the original state of the data. This approach maintains the integrity of the dataset by marking which values are original and which are synthetic (imputed). Here are the steps to implement this approach:
Identify Missing Values: Determine which features contain missing values.
Impute Missing Values: Continue with median imputation or choose another method (mean, mode, regression, etc.) to fill missing values.
Create Indicator Variables: For each feature that had missing values, add a new binary feature. This feature should be '1' if the original value was missing and imputed, and '0' otherwise.
Data Integration: Integrate these new binary features into the existing dataset. This maintains a record of where data imputation occurred, allowing models to potentially weight these observations differently.
Model Adjustment: Adjust machine learning models to account for these new features, which might involve considering interactions between these binary indicators and other features.
Reference
"Feature Engineering for Machine Learning" by Alice Zheng and Amanda Casari (O'Reilly Media, 2018), especially the sections on handling missing data.
Scikit-learn documentation on imputing missing values: https://scikit-learn.org/stable/modules/impute.html
NEW QUESTION # 57
A machine learning engineer is trying to scale a machine learning pipeline by distributing its feature engineering process.
Which of the following feature engineering tasks will be the least efficient to distribute?
- A. Creating binary indicator features for missing values
- B. Target encoding categorical features
- C. Imputing missing feature values with the mean
- D. One-hot encoding categorical features
- E. Imputing missing feature values with the true median
Answer: E
Explanation:
Among the options listed, calculating the true median for imputing missing feature values is the least efficient to distribute. This is because the true median requires knowledge of the entire data distribution, which can be computationally expensive in a distributed environment. Unlike mean or mode, finding the median requires sorting the data or maintaining a full distribution, which is more intensive and often requires shuffling the data across partitions.
Reference
Challenges in parallel processing and distributed computing for data aggregation like median calculation: https://www.apache.org
NEW QUESTION # 58
A data scientist has been given an incomplete notebook from the data engineering team. The notebook uses a Spark DataFrame spark_df on which the data scientist needs to perform further feature engineering. Unfortunately, the data scientist has not yet learned the PySpark DataFrame API.
Which of the following blocks of code can the data scientist run to be able to use the pandas API on Spark?
- A. import pandas as pd
df = pd.DataFrame(spark_df) - B. import pyspark.pandas as ps
df = ps.DataFrame(spark_df) - C. spark_df.to_pandas()
- D. import pyspark.pandas as ps
df = ps.to_pandas(spark_df)
Answer: B
Explanation:
To use the pandas API on Spark, the data scientist can run the following code block:
import pyspark.pandas as ps df = ps.DataFrame(spark_df)
This code imports the pandas API on Spark and converts the Spark DataFrame spark_df into a pandas-on-Spark DataFrame, allowing the data scientist to use familiar pandas functions for further feature engineering.
Reference:
Databricks documentation on pandas API on Spark: pandas API on Spark
NEW QUESTION # 59
......
Pass Databricks Databricks-Machine-Learning-Associate Premium Files Test Engine pdf - Free Dumps Collection: https://www.prep4pass.com/Databricks-Machine-Learning-Associate_exam-braindumps.html
Databricks-Machine-Learning-Associate Exam Info and Free Practice Test | Prep4pass: https://drive.google.com/open?id=18oZduXXaiKg_0vUBmcOxKE0rxkqdU92c